The science of Genomics derives from the study of Genetics. However, as opposed to Genetics, Genomics is looking at how our genes work in a larger context. That is, through Genomics, we look at how the DNA sequence of all our genes influences one or more biological outcomes. In other words, Genomics is an extension of Genetics, and this was made possible by the tremendous technological progress acquired during the last decades. If, 30 years ago, a scientist could look at only one gene, and sequence it using a painstaking and costly method, now we can sequence the entire human genome for only few thousand dollars.
It is important to understand that Genomics works with up to millions of variables. For instance, each variable could be represented by one nucleotide that can be different, at the same position in one gene, between two individuals. It is estimated that the human genome could have up to 10 million positions where nucleotides could vary between individuals. As a consequence, it is important to understand that Genomics requires very sophisticated mathematical methods that have to be employed (what we call statistical testing) in order to properly ascertain associations of genomic variations with health outcomes.
Here you will understand the structure of DNA, how DNA is replicated (multiplied) during cell division, how DNA can be altered during its replication, and the roles that DNA has as the keeper of all the information necessary for us to exist.
DNA structure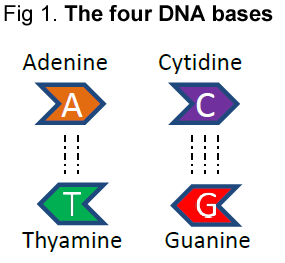
DNA is made of nucleotides. These are quite complex molecules, composed of a nitrogenous base, a sugar molecule, and a phosphate residue. But this is not important to remember. What is important to remember is that there are only 4 types of nucleotides (bases): adenine (A), cytosine (C), thymine (T) and guanine (G). Another important thing is to remember that each of these bases has the affinity to interact by weak (non-chemical) bonds with only one out of the other three nucleotides (we will see why this is important when we will talk about the redundancy of genetic information). Figure 1 depicts the symbols of these nucleotides, and their specific affinities (doted lines; note that G-C pairs form stronger bonds than the A-T pairs; we call these base pairs).
On the other hand, each nucleotide can form chemical bonds with any of the other 3 nucleotides (Figure 2). This way, any combination of nucleotides can be formed (a big linear molecule): this is what we call a DNA strand.

But DNA is double-stranded. A DNA molecule is formed by 2 strands of DNA, kept together by the weak bonds that we were talking about two paragraphs above. Figure 3 depicts the simplified structure of a DNA molecule. In humans, such DNA mo lecules are extremely long. Each DNA molecule hosts thousands of genes, where each gene is comprised of hundreds to many thousands nucleotides. So you have to see the DNA molecules as giant molecules, which are hosting a tremendous amount of genetic information. Just to amaze you, the total length of the entire DNA in a tiny human cell is over 9 feet (3 meters). This is huge, don’t you think?
lecules are extremely long. Each DNA molecule hosts thousands of genes, where each gene is comprised of hundreds to many thousands nucleotides. So you have to see the DNA molecules as giant molecules, which are hosting a tremendous amount of genetic information. Just to amaze you, the total length of the entire DNA in a tiny human cell is over 9 feet (3 meters). This is huge, don’t you think?
So how is it possible that a 9-foot long DNA be hosted in a tiny cell (a microns-sized cell that is)? The DNA is packed around many units of proteins (histones), such that it can fit in the cell (Figure 4). Remember the string that you buy and use with your grass trimmer? You buy it neatly packed. Similarly, the DNA molecule is wrapped around many histones, until the space it occupies becomes so small, that it can fit into a cell. Each human cell has 23 pairs of chromosomes: one set comes from the mother, the other set comes from the father. Thi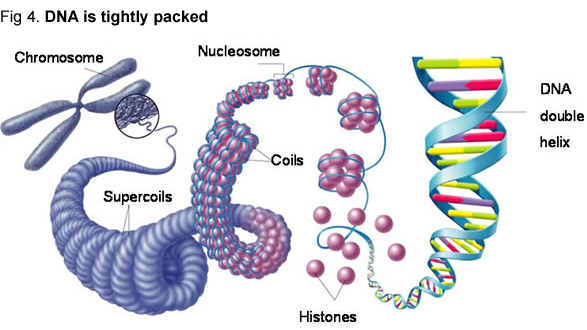 s is important, because now we realize (or this is what we thought until recently) that each human cell has 2 copies of each gene, each copy being inherited from one parent.
s is important, because now we realize (or this is what we thought until recently) that each human cell has 2 copies of each gene, each copy being inherited from one parent.
DNA replication
When a cell divides into two daughter cells, it first has to ensure that the new cells get the normal amount of DNA. So, before a cell divides, it has to generate another copy of its own set of chromosomes, such that each daughter cell to get the normal amount of DNA. How does this happen? Figure 5 depicts the process of DNA replication. The double stranded DNA molecule is split in two, and each strand becomes the template for generating two new strands, whose sequences are complementary to the original ones. This way, at the end of DNA replication (before cell division), the cell ends up with a double amount of DNA, which will be equally split to its daughter cells.
Why is it important to understand DNA replication? Because this process is the root of what we will talk about later: accidents in how precisely the DNA is replicated (mutations). It is important to understand that these “defects” in DNA replication are the reason why each of us has a slightly different genome than any other human in the world (even “identical” twins are not entirely identical). Each of us is unique due to these “accidents” in DNA replication. Other mutations can also happen outside DNA replication phase. Such mutations are usually initiated by chemical or physical agents such as exposure to UV light, or to harmful and reactive chemicals introduced in our body. Under these influences, our DNA sequence can also mutate. Once a mutation is established, it is very important to understand that it will be permanently inherited by the other cells that derive from the damaged cell. Going further, our kids inherit all these genetic differences that occurred in our DNA, or in our ancestors’ DNA. Once these mutations are established and spread throughout multiple generations, we call these genetic variations.

DNA repair
This sounds scary indeed! Fortunately, it turns out that only few of these mutations are actually maintained. This is because cells have proteins that “police” the entire process of DNA replication. These proteins (DNA repair apparatus) can identify immediately if a nucleotide has been wrongly inserted (meaning that it does not follow the pattern of the template DNA strand). Once a mutation is discovered, these proteins remove that wrong nucleotide, and replace it with the right one. Therefore, only a minor fraction of the occurring mutations survive the process of DNA replication (and this is because the DNA repair mechanisms are imperfect – they cannot catch/recognize ALL these mutations, but rather most of them).
Genes and how they work
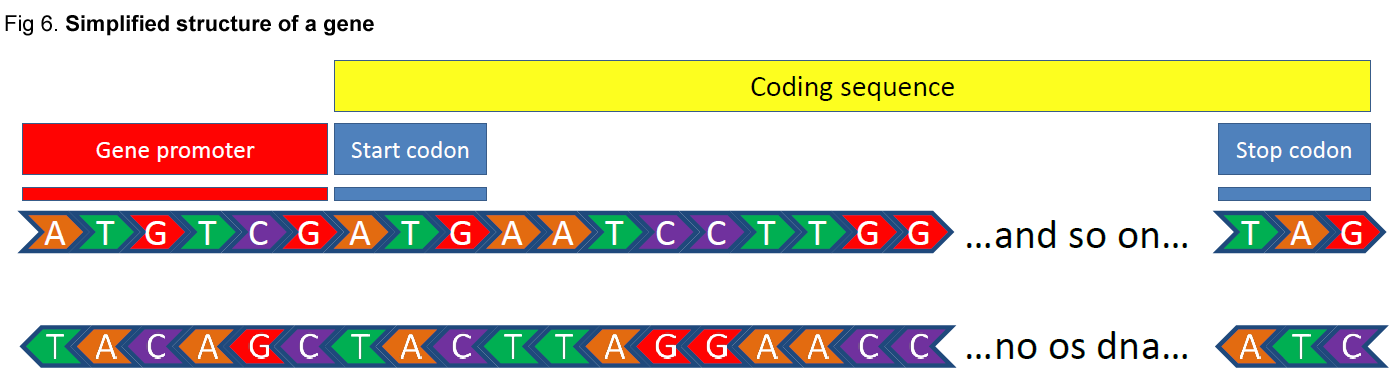
Now that we know how DNA is structured, we can understand what a gene is, and how it works. A gene is a portion of the double stranded DNA molecule, which codes the information required for the synthesis of a protein. Figure 6 depicts the simplified structure of a gene. As a protein consists of a chain of amino acids, each amino acid species is coded by a sequence of 3 nucleotides (codon). At the front of the gene (left side), there is a DNA sequence called promoter. The promoter does not code information, but it is rather essential for the activation of gene. A promoter has to be switched “on” in order for a gene to be active. Conversely, if the promoter is switched “off”, the gene will not express itself. This way, a gene can be turned “on” or “off” by the state of its promoter. A promoter is activated when certain proteins (transcription factors) bind to it.
The process is this (Figure 7):
1) First the double stranded DNA is dissociated;
2) One of the DNA strands serves as template for RNA synthesis. RNA is a molecule similar to a DNA strand,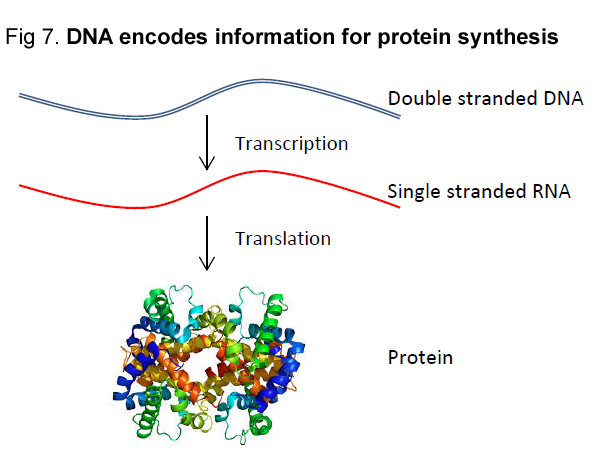 but instead of T has a Uracil (U) nucleotide. Basically, RNA serves as the intermediate molecule that carries the genetic information stored by the DNA to the outside of the cellular nucleus. Once the RNA has exited the nucleus, it serves as template for protein synthesis: each codon (copied according to the DNA template sequence), instructs the cell which amino acid to add to the protein sequence. Once the entire RNA molecule is decoded, the protein is made. At this point, we have a functional molecule (the protein) which will perform a certain function in or outside the cell. It is important to remember that the entire catalogue of proteins made in our cells is responsible for all cellular functions, including the generation of many active metabolites (such as vitamins, fatty acid species, small molecules, amino acids, small hormone molecules, etc.).
but instead of T has a Uracil (U) nucleotide. Basically, RNA serves as the intermediate molecule that carries the genetic information stored by the DNA to the outside of the cellular nucleus. Once the RNA has exited the nucleus, it serves as template for protein synthesis: each codon (copied according to the DNA template sequence), instructs the cell which amino acid to add to the protein sequence. Once the entire RNA molecule is decoded, the protein is made. At this point, we have a functional molecule (the protein) which will perform a certain function in or outside the cell. It is important to remember that the entire catalogue of proteins made in our cells is responsible for all cellular functions, including the generation of many active metabolites (such as vitamins, fatty acid species, small molecules, amino acids, small hormone molecules, etc.).
In the end, we are what we are, and we are build this way, because all this marvelous machinery is generated from the information stored in our DNA.
I will finish this section with a question: if all the cells in my body have the same DNA (same genome), how come I have so many different types of cells? What makes a skin cell to be different from a liver cell? The answer is given by the epigenetic regulation of genes: we will learn that, although each cell in our body has the same genome, different genes are active in different cells. And this is what epigenetic mechanisms do.